A simple shift in how machines "pay attention" has revolutionized AI. In just a few years, we’ve moved from basic chatbots to sophisticated tools like ChatGPT and AI writing assistants. At the heart of this transformation are transformers and attention mechanisms—concepts that aren’t magical but instead focus on how information flows and how machines can prioritize certain aspects of data.
These innovations have enabled machines to better understand language and context, becoming the foundation of modern AI. If you’ve ever wondered what powers today’s smartest models, it all starts with these breakthrough concepts.
Before transformers, most natural language processing models employed systems that processed text like a human would process a sentence—a word at a time. These were known as recurrent neural networks (RNNs). Although the concept worked, it didn't scale. RNNs tended to forget previous components of the sentence by the time they reached the end. Long-term connections between words became vague. Machines grappled with subtlety, nuance, and memory.
Transformers threw out the old rulebook. They said, what if we didn't read text word for word but the whole thing at once? That's what made them revolutionize. Rather than creeping through a sentence, transformers consume the whole sequence at once and process the context in parallel. This provides the model with a bird' s-eye view of the sentence and allows it to see more sophisticated relationships between words, even if they're really far apart.
This shift brought massive improvements in both speed and understanding. Models could be trained faster, with better accuracy. But there was still a deeper piece that made it all tick—the attention mechanism. Without that, transformers would just be another fancy architecture. Attention is what gives them their edge.
The attention mechanism is simple in concept but powerful in practice. Imagine reading a sentence: “The bird that was sitting on the fence flew away.” To understand “flew,” your brain connects it back to “bird,” not “fence.” You don’t treat all words equally—you focus more on the important ones. That’s exactly what attention mechanisms do. They assign a score to each word in relation to every other word and decide which ones to “focus” on.
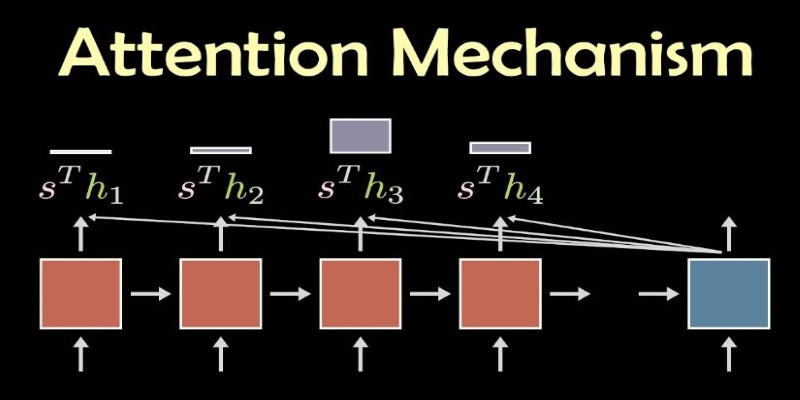
When a transformer reads a sentence, it breaks it down into smaller parts called tokens. For each token, it computes how much attention it should pay to all the other tokens. These attention scores are stored in something called an attention matrix. From that matrix, the model decides which words influence the meaning of the current word the most.
This is done using key, query, and value vectors—three different views of each word. A word’s “query” checks how well it matches the “keys” of the other words. If the match is strong, the model pulls in the associated “value.” That’s the essence of attention. Every word becomes aware of the others, and the model creates a web of influence across the sentence.
This is what allows the model to maintain nuance and structure across long passages of text. Whether the sentence is five words or five hundred, attention mechanisms help it stay grounded in meaning.
In a transformer, attention doesn't happen once—it happens in layers. Each layer applies the attention mechanism and passes its output to the next, creating depth. At the lower levels, the model learns simple patterns, like grammar or punctuation. As you go higher, the model starts picking up on themes, tone, and abstract relationships.
Within each layer, there’s something called self-attention. This means that every word attends to every other word, including itself. It’s like every word is holding a conversation with every other word, trying to understand its place in the sentence. Self-attention is what makes transformers incredibly good at capturing the structure and relationships in language.
Another key trick is multi-head attention. Instead of having a single view of how attention works, transformers split it into multiple "heads," each learning a different kind of relationship. One head might focus on subject-verb agreement, while another might track pronoun references. By combining all these heads, the model develops a richer and more robust understanding of the input.
This design—multi-layer, multi-head self-attention—is what gives transformers their remarkable flexibility. Whether translating languages, summarizing articles, or generating code, the model leans on these patterns to find meaning and structure.
After transformers proved their potential, models like BERT (Bidirectional Encoder Representations from Transformers) emerged. Using a transformer encoder, BERT understood the text in both directions, making it highly effective for tasks such as question answering, sentiment analysis, and language comprehension.

Then came GPT (Generative Pre-trained Transformer), which flipped the focus from understanding to generation. Instead of just analyzing text, GPT could write it—predicting the next word one step at a time, using everything it had seen before. GPT's brilliance was that it used a decoder-based transformer structure that was optimized for generating coherent and creative text.
As the models grew—GPT-2, GPT-3, and beyond—the power of transformers became undeniable. Large language models trained on massive datasets were suddenly capable of writing essays, poems, stories, code, and more. And it wasn’t just words. These models could be adapted for images, speech, and other kinds of data, turning transformers into the Swiss army knife of AI.
The foundation remained the same: attention mechanisms layered within transformer blocks. But the scale, training data, and compute power changed. And with that, the output quality skyrocketed.
Today, tools like ChatGPT use a blend of these ideas. They rely on massive transformer models that are fine-tuned with human feedback and optimized to keep conversations flowing naturally. None of this would've been possible without attention.
Transformers and attention mechanisms have fundamentally reshaped AI by enabling machines to understand and generate language with greater accuracy and context. By allowing models to focus on relevant parts of input data, they improve efficiency and scalability. This breakthrough has led to the development of advanced large language models like GPT, which are capable of handling complex tasks. As AI continues to evolve, transformers will remain central to its progress, driving innovations across various domains.

Master MLOps to streamline your AI projects. This guide explains how MLOps helps in managing AI lifecycle effectively, from model development to deployment and monitoring

How to visualize proteins using interactive, AI-powered tools on Hugging Face Spaces. Learn how protein structure prediction and web-based visualization make research and education more accessible

Learn what a pictogram graph is, how it's used, and why it's great for data visualization. Explore tips, examples, and benefits.

How AWS Braket makes quantum computing accessible through the cloud. This detailed guide explains how the platform works, its benefits, and how it helps users experiment with real quantum hardware and simulators

How leveraging AI into your business can help save time, reduce repetitive tasks, and boost productivity with simple, smart strategies

The Black Box Problem in AI highlights the difficulty of understanding AI decisions. Learn why transparency matters, how it affects trust, and what methods are used to make AI systems more explainable

AI in wearable technology is changing the way people track their health. Learn how smart devices use AI for real-time health monitoring, chronic care, and better wellness

Zero-click buying revolutionizes eCommerce with effortless shopping and boosting sales, but privacy concerns must be addressed

Nvidia Acquires Israeli AI Startup for $700M to expand its AI capabil-ities and integrate advanced optimization software into its platforms. Learn how this move impacts Nvidia’s strategy and the Israeli tech ecosystem

Knowledge representation in AI helps machines reason and act intelligently by organizing information in structured formats. Understand how it works in real-world systems

How to get started with sentiment analysis on Twitter. This beginner-friendly guide walks you through collecting tweets, analyzing sentiment, and turning social data into insight

Boost your Amazon sales by optimizing your Amazon product images using ChatGPT. Learn how to craft image strategies that convert with clarity and purpose